Discover how stable diffusion works in simpler terms. Learn how this transformative AI model generates images from text and impacts the future of deep learning.
Understanding AI Image Generators
AI image generators are advanced computer models trained to create images that resemble real-life objects, scenes, or concepts. These models use a technique called deep learning.
AI image generators are super cool machines that can create pictures from words! These machines are designed like our brains, learning from information and creating new stuff based on what they learn.
Imagine writing a description of a unique creature, and these machines could bring your creature to life in a picture!
For example, “a mythical creature cat with bunny ears”.

Basics of Stable Diffusion
Stable Diffusion is an advanced technology that allows computers to generate realistic images based on written descriptions or prompts. It works by training a model on a large dataset of images and corresponding text descriptions.
Stable Diffusion is like an upgraded version of these cool machines. It uses something called deep learning, which is like having a super-smart brain. This brain can take a piece of text and turn it into a picture.
So how does Stable Diffusion work?
Simply put, it works by squishing the data into a smaller form called latent space, then adding and subtracting noise (like static you see on an old TV) to create the image. It’s like making sense out of chaos!
- Note: check out my Stable Diffusion simple installation guide for Windows, if you don’t have it already.

Latent Spaces: The Foundation of Stable Diffusion
Latent space is the process of taking a whole bunch of data and packing it down to only the most important parts. This process helps the machine work more efficiently and focus on the main stuff.
Latent space is a major part of how Stable Diffusion works. Think of latent space like packing a suitcase for a trip. You can’t take your entire wardrobe, right? You only pack the most essential stuff.
To create a latent space, we use a technique called dimensionality reduction. This process involves transforming the high-dimensional data of an image into a lower-dimensional representation. It’s like taking a complex picture and simplifying it to capture the essential features.
This compressed representation saves computational resources, which makes it easier and faster for the model to work with the data.
It also allows for manipulation and interpolation. This means we can smoothly transition between different images or modify specific attributes.
For example, you could take an image of a cat and morph it into an image of a cat with bunny ears by smoothly navigating through the latent space.
- Note: check out a list of 40+ things you can do in Stable Diffusion.

The Mechanism of Diffusion Models
Diffusion models are the secret sauce behind Stable Diffusion. They work by adding and removing noise in a step-by-step process to create the final picture.
It’s like an artist first sketching rough lines (that’s the noise) and then refining the lines until they have a finished drawing.
Imagine you have a blank canvas, and you want to create a beautiful painting. Instead of starting from scratch, diffusion models modify an existing image by adding and removing noise.
Adding the noise is called forward diffusion, and removing it is called backward diffusion. The picture goes from a noisy mess to a clear and transformed image, all thanks to the text you fed the machine.
Understanding how Stable Diffusion works is like getting a peek into the future of what AI can do. It’s pretty amazing how it’s changing the way we create and imagine!
I also ran some tests to find out if Stable Diffusion generated images are unique from one another, and the short answer is – yes, mostly.

U-Net: The Architect of Noise Reduction
U-net is a special type of neural network that is trained to estimate the amount of noise present in an image and then subtract that noise, step by step, to reveal the underlying image.
Picture U-Net as an artist, but instead of painting, its job is to clean up noise from images. What’s noise? Imagine a high-def picture of your favorite celeb, and then someone doodles all over it with a marker. That’s noise!
U-Net is like a super cool AI sponge, soaking up all that extra ‘marker scribble’ and leaving us with a perfect picture. It’s built in a U-shape, hence the name. Pretty clever, right?
For a more complex and mathematical understanding of how stable diffusion works, I suggest watching the video below:
How Stable Diffusion is Trained
Training Stable Diffusion involves teaching the model to generate high-quality images based on text descriptions.
It’s like training your dog, but in this case, you’re training an AI.
To start, Stable Diffusion gets a set of images. This can be anything – cars, dogs, people, food – whatever you want the AI to learn. This set of images is like a photo album, called a ‘training set’.
Next up is the training phase. This is where Stable Diffusion learns to create images from text. How? Well, it’s shown an image and some text that describes it. The AI then tries to create an image based on that text.
At first, the AI might not do a great job. The image it creates might look like a Picasso painting during his Cubist period. But every time the AI gets it wrong, it’s corrected. This is where the ‘training’ comes in.
The training process often involves multiple iterations or epochs, where the model goes through the entire dataset many times to improve its performance.
This repetitive learning helps the model to generalize and generate high-quality images not only from the training dataset but also for new text descriptions.
With enough practice, the AI gets better and better at understanding the link between the text and the image. So, the more it trains, the better it becomes at generating new images from text prompts.
It’s like the AI is in school, and the more it studies and learns from its mistakes, the better it gets at its job.
Ultimately, Stable Diffusion learns how to create realistic, high-quality images from any text description. Kind of like a supercharged, art-producing brain!
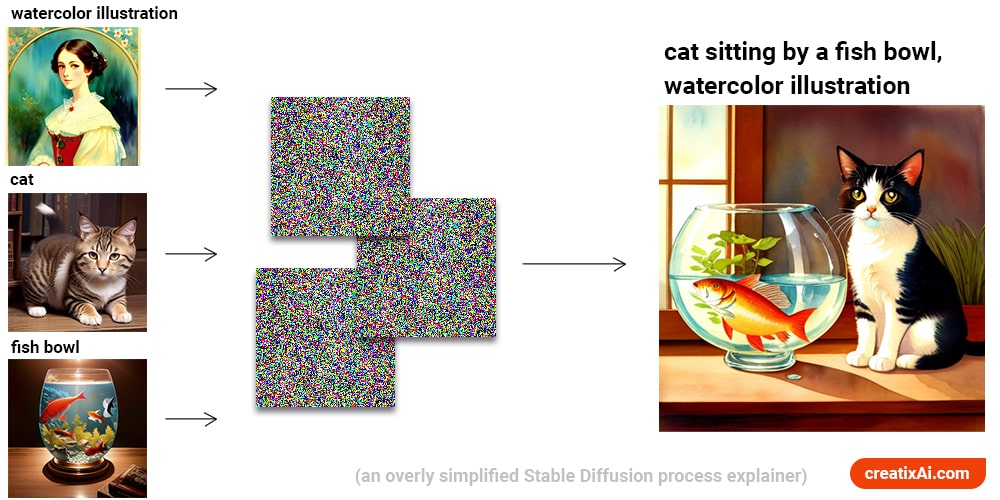
The Role of Text in Stable Diffusion
Ever wondered if we could turn words into pictures? With Stable Diffusion, we can!
This process starts with language transformers that translate words into code that the AI can read – think of it as a secret AI language.
In the context of Stable Diffusion, the text is transformed into a format that the model can understand. This is typically done through a process called tokenization, where words are converted into numerical representations or tokens.
These coded words are then used to guide the U-Net in creating an image. It’s like having a secret blueprint that tells the AI what the final image should look like!
The text prompt acts as a guideline or description for the generated image. It can specify objects, scenes, attributes, or even emotions that should be present.
For example, if the prompt says “a woman with red hair at a park,” the model will generate an image that represents a park scene with a red-haired woman.
This enables us to have control over the generated image with specific instructions. If something isn’t to our liking, we can keep all of the settings the same but adjust the prompt until we get exactly what we envisioned.

Why Stable Diffusion?
Creating images from words sounds cool, but it can also be pretty heavy on your computer’s brain. So, what’s the solution? Enter Stable Diffusion.
Stable Diffusion works on a simpler version of the image, a sort of rough sketch. This makes things faster and easier for your computer without losing the final picture quality. It’s like the fast-forward button for image generation!
Still, let’s discuss some advantages of using Stable Diffusion:
- First and foremost, Stable Diffusion can create realistic and visually appealing images that closely match the provided text. It can capture fine details, textures, and overall coherence in the generated images.
- Another advantage of Stable Diffusion is its stability and consistency in generating images. The diffusion process used in the model helps to create stable and reliable results with a consistent output.
- Stable Diffusion also offers control and customization options. Users can adjust various parameters to influence the output and better match specific requirements or preferences.
- Stable Diffusion also leverages the power of deep learning and neural networks. The model learns from a large dataset of image-text pairs through the training process, making it a versatile tool for various applications.
- Finally, it has been designed to operate efficiently, utilizing latent spaces and optimization techniques to generate images effectively. This means that it can deliver results within reasonable time frames, even on standard hardware setups.

Applications and Possibilities of Stable Diffusion
Stable Diffusion isn’t just for fun. It has some pretty real uses too. The possibilities are huge!
Looking to the future, we might even see it used professionally in medicine, virtual reality, or 3D modeling. We’re on the edge of a whole new world of AI-driven creation!
Here are some of the exciting applications and possibilities of Stable Diffusion:
- Artistic Creation – provide text prompts with your vision to produce captivating visual artwork.
- Design – from logos to mockups, with the right prompting, everything is within reach.
- Visualization – architects and interior designers can use it to generate realistic visualizations of spaces to make quick changes or help clients better understand their vision.
- Content Generation – images for websites, ads, and social media posts.
- Illustration – provide prompts to help with storytelling in your books and comics.
- Personalization – make changes to current photographs with img2img, inpainting or ControlNet.
- Video creation – making music videos, short films, and gifs.
- and much, much more!
You can try Stable Diffusion online on their official Hugging Face space. See what new and creative uses you can come up with!

Key Takeaways
Stable Diffusion is an advanced AI technology that can generate realistic images from text prompts. It utilizes a process called deep learning, which is akin to an intelligent brain making sense of a text and transforming it into a picture.
This technology works through a process of dimensionality reduction, creating a ‘latent space’. This is like packing only the essentials for a trip, with the AI focusing on the key features of an image.
Latent spaces save computational resources, speeding up the AI’s work. They also allow us to manipulate images smoothly or alter specific attributes.
Diffusion models are the secret behind Stable Diffusion. They work in a step-by-step process, adding and subtracting noise to create the final image. This process is much like how an artist would refine a sketch into a finished piece of art.
U-Net, a type of neural network, is designed to estimate the noise present in an image and gradually remove it, revealing the intended image.
Training Stable Diffusion involves teaching the model to produce high-quality images based on text prompts. The process involves numerous iterations or epochs, enabling the AI to improve its performance over time.
Text plays a pivotal role in Stable Diffusion. Words are transformed into a format the AI can understand, guiding the image creation process. The text acts as a blueprint for the image to be generated.
Stable Diffusion is advantageous due to its ability to create visually appealing, realistic images that closely match provided text. It also provides stability, control, customization options, and efficient operation.
Applications of Stable Diffusion range from artistic creation and design to visualization, content generation, illustration, and more. This innovative technology promises to open up new horizons in AI-driven creation.
Frequently Asked Questions
What is Stable Diffusion in AI?
Stable Diffusion is a cutting-edge technology in the realm of AI. It’s a type of model that generates realistic, high-quality images from textual descriptions.
How does Stable Diffusion generate images?
Stable Diffusion generates images in a step-by-step process. First, it compresses data into a smaller form known as latent space. It then adds and removes noise from this space in a systematic manner. The image evolves from a noisy form to a clear, final picture, guided by the text you provide.
What is latent space in Stable Diffusion?
Latent space in Stable Diffusion refers to the condensed form of data, essentially a compressed representation of the most crucial elements. It serves as the starting point for image creation.
What is CFG value in Stable Diffusion?
CFG value, or Configuration Value, in Stable Diffusion, refers to the various parameters and settings that influence the image generation process. By tweaking CFG values, users can influence the final output, tailoring it to specific requirements or preferences.
Is Stable Diffusion free?
Stable Diffusion is free to use when installed locally on your own computer. Other platforms offer it for free or for an extra charge.
Is Stable Diffusion the best?
Stable Diffusion is certainly a powerful tool for generating images from text, but whether it’s the ‘best’ depends on individual needs. It offers realistic and consistent results, efficient operation, and customization options, which may make it the ideal choice for many applications.
Is Stable Diffusion local?
Stable Diffusion models can be run locally and on the cloud, depending on the computational resources and needs of the user.







